字节跳动旗下的豆包大模型近期搞活动,送5亿Tokens,平时也基本用不上,就拿来折腾一下博客,给博客加上AI总结功能。其实这个模版自带有一个Gemini的总结,但是有地区限制,用起来也不够快,就替换成豆包吧。原本以为会很简单,还是被各种小问题折磨,最终还是借助ChatGPT帮忙修改代码才完成。
注册豆包大模型
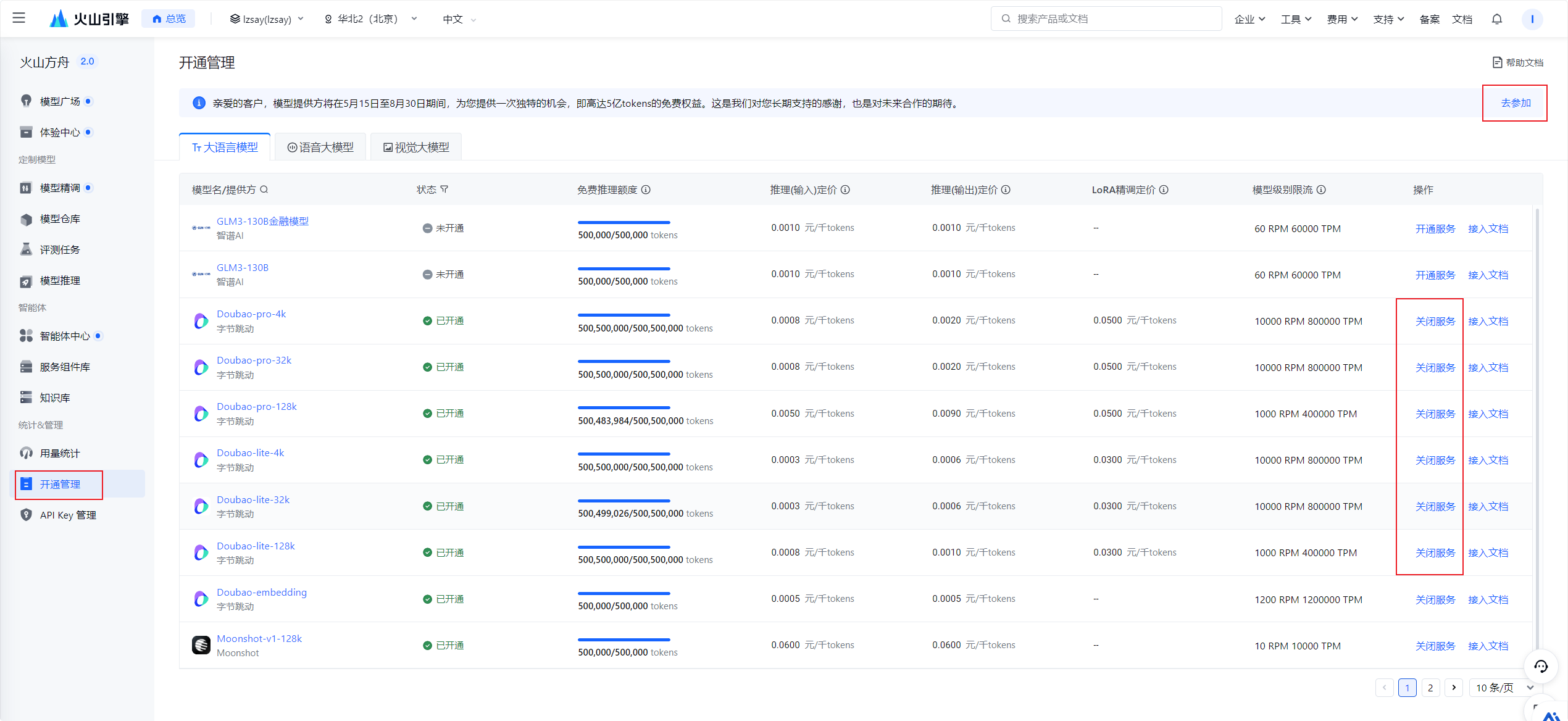
详细的注册过程不在写了,之前去火山引擎注册即可,注册后要先去账户下的开通管理中开通相关模型,开通默认是送50万tokens,需要点击顶部的活动链接,同意参与测试即可获得额外的5亿tokens额度。==需要注意,参加活动后,通过豆包模型的对话数据会传给豆包模型进行数据训练,介意的不要参加和注册这个活动。==
部署simple-one-api
开通后我是直接尝试把豆包API集成到博客,可是会一直报跨域错误。用反代的方式貌似也不行,折腾了好久也没解决,后面搜索到simple-one-api项目,目的是将其他模型的API接口转换为OpenAI的接口方式,可以供一些GPT工具方便调用。
我是在VPS上直接通过Docker一键部署,其他部署方式可以参考github页面。
在Docker部署前先建立一个config.json的配置文件。
mkdir .doubao
cd .doubao/
touch config.json
编辑config.json文件。nano config.json
{
"server_port": ":9099",
"load_balancing": "random",
"services": {
"huoshan": [
{
"models": ["doubao-32k"],
"enabled": true,
"credentials": {
"access_key": "xxx",
"secret_key": "xxx"
},
"model_map":{
"doubao32k": "ep-20240612090709-xxxxx"
},
"server_url":"https://ark.cn-beijing.volces.com/api/v3"
}
]
}
}
models可以自定义,model_map、access_key和secret_key需要去火山引擎的后台查找。
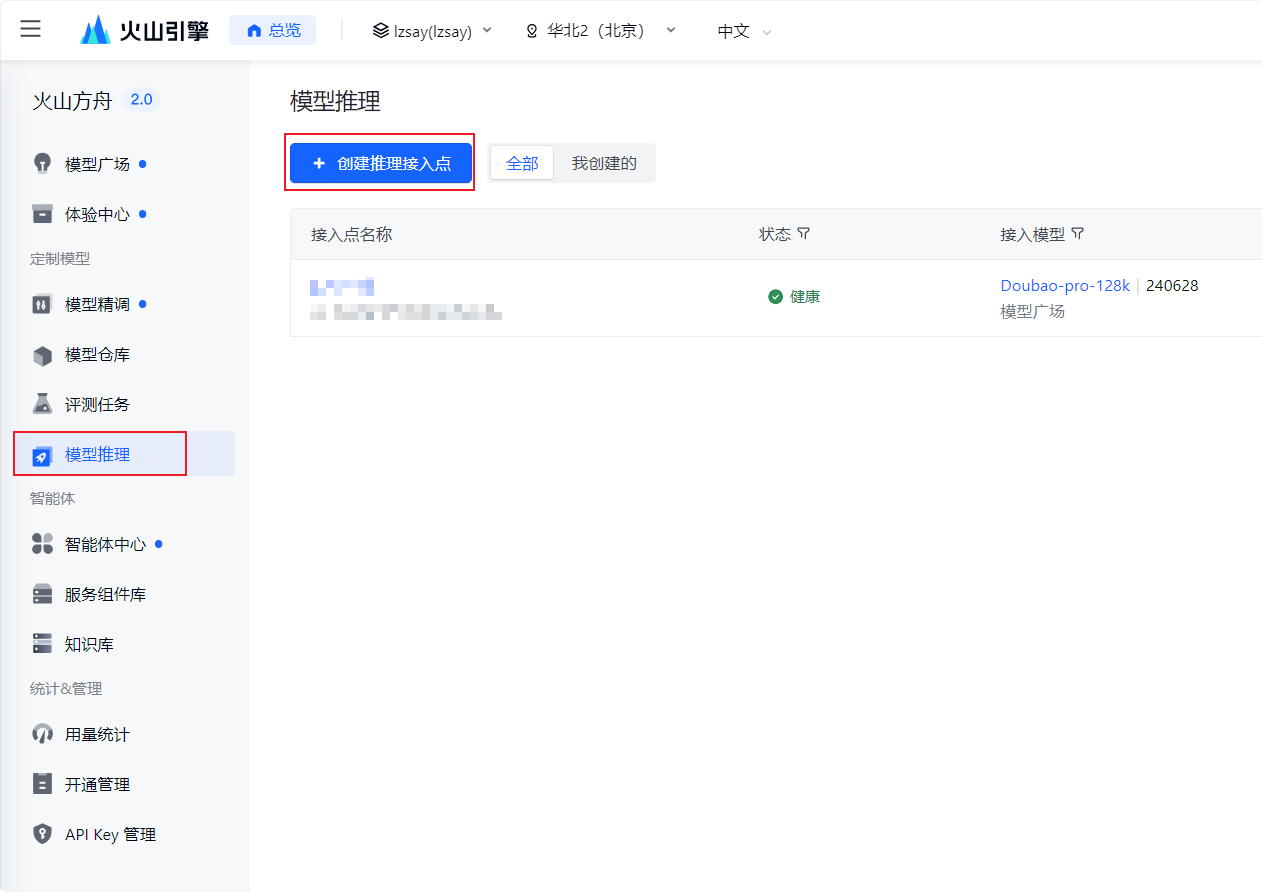
在模型推理中创建推理接入点,创建完成即可获得ep-开头的模型接入点代码。
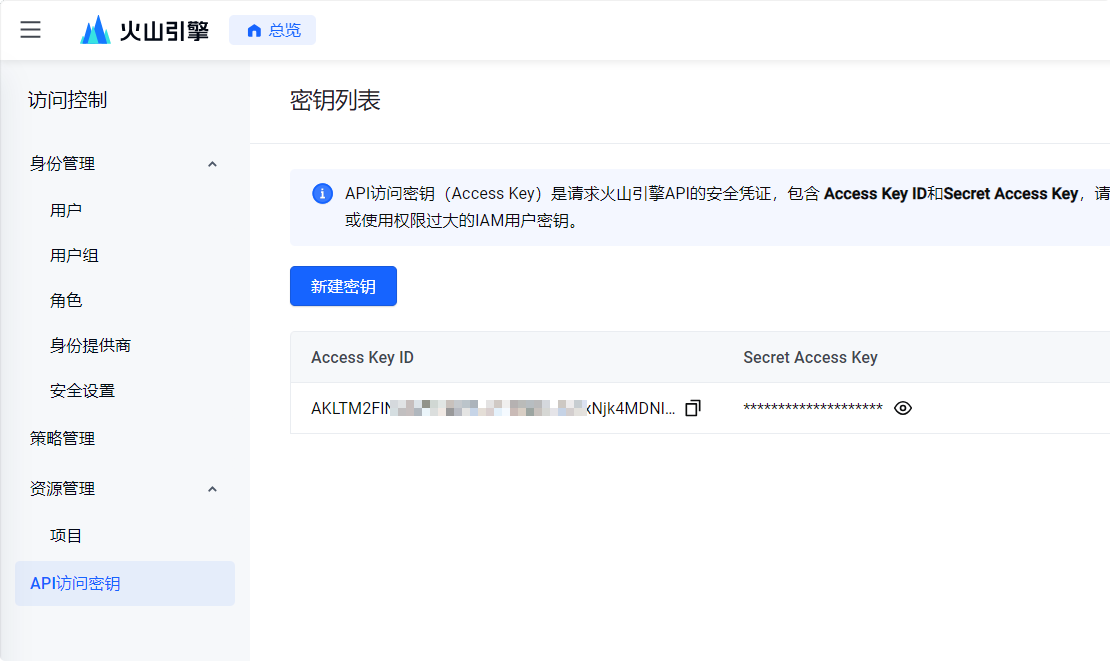
在API访问密钥页面新建密钥,将access_key和secret_key填入config.json中。
保存后,我们就可以用Docker一键部署了。
docker run -d --name simple-one-api -p 9090:9090 -v ~/.oneapi/config.json:/app/config.json fruitbars/simple-one-api
部署完成后可以分配一个自定义的域名,方便调用,可以参考博客折腾记录中的操作。
部署后,直接访问可能是404,这个无所谓,可以用在线API调试工具测试一下。
POST https://gemini.lzsay.com/v1/chat/completions
{
"model": "doubaopro128k",
"messages": [
{ "role": "system","content":"你是豆包,是由字节跳动开发的 AI 人工智能助手。"},
{ "role": "user", "content": "你是谁?" } ]
}
结果正常返回如下:
{
"id": "02172077149174940571e3ce5f26177b37c29bf9d076c3b574089",
"object": "chat.completion",
"created": 1720771496,
"model": "doubao-pro-128k-240628",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "我是豆包,是一个可以回答各种问题、提供信息和进行交流的人工智能。无论是关于历史、科学、技术、文化,还是日常生活中的各种话题,都可以随时问我哦! "
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 31,
"completion_tokens": 44,
"total_tokens": 75
},
"HttpHeader": {
"Content-Length": [
"534"
],
"Content-Type": [
"application/json; charset=utf-8"
],
"Date": [
"Fri, 12 Jul 2024 08:04:56 GMT"
],
"Server": [
"istio-envoy"
],
"X-Client-Request-Id": [
"20240712080450000018CC78A24B2557BD"
],
"X-Envoy-Upstream-Service-Time": [
"4437"
],
"X-Request-Id": [
"02172077149174940571e3ce5f26177b37c29bf9d076c3b574089"
]
}
}
博客集成
基于现有的gemini模型改造,直接替换了gemini.html中的链接,运行页面会没有结果展示,通过控制台发现实际是有生成结果,只是分了好多字节,经过chatgpt分析是因为用了逐步解析。需要改为整体响应。

并直接给出了代码修改建议:
// 读取整个响应体
const responseText = await res.text();
// 解析JSON数据
const data = JSON.parse(responseText); const content = data.choices[0].message.content;
// 显示结果
postAIResult.textContent = `内容: ${content}`;
直接替换掉博客模版中gemini.html的结果解析部分,即可正常运行,顺便把提示语也换成中文的。
gemini.html完整代码:
<div class="post-ai" onclick="geminiAI()">
<img alt="Static Badge" src="https://shields.lzsay.com/badge/DouBao-文章摘要-blue.svg?logo=data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIxZW0iIGhlaWdodD0iMWVtIiB2aWV3Qm94PSIwIDAgMjQgMjQiPjxwYXRoIGZpbGw9Im5vbmUiIHN0cm9rZT0iI2ZmZmZmZiIgc3Ryb2tlLWxpbmVjYXA9InJvdW5kIiBzdHJva2UtbGluZWpvaW49InJvdW5kIiBzdHJva2Utd2lkdGg9IjIiIGQ9Im0yMS42NCAzLjY0bC0xLjI4LTEuMjhhMS4yMSAxLjIxIDAgMCAwLTEuNzIgMEwyLjM2IDE4LjY0YTEuMjEgMS4yMSAwIDAgMCAwIDEuNzJsMS4yOCAxLjI4YTEuMiAxLjIgMCAwIDAgMS43MiAwTDIxLjY0IDUuMzZhMS4yIDEuMiAwIDAgMCAwLTEuNzJNMTQgN2wzIDNNNSA2djRtMTQgNHY0TTEwIDJ2Mk03IDhIM20xOCA4aC00TTExIDNIOSIvPjwvc3ZnPg==">
</div>
<style>
@keyframes spin { from {transform: rotate(0deg);}to {transform: rotate(360deg);} }
.post-ai-result svg{animation: spin 1s infinite linear;}
</style>
<script>
let postAI = document.querySelector(".post-ai")
let postTile = document.querySelector(".post-title a").textContent
async function geminiAI() {
postAI.insertAdjacentHTML('afterend', '<div class="post-ai-result"><svg xmlns="http://www.w3.org/2000/svg" width="1.5rem" height="1.5rem" viewBox="0 0 24 24"><path fill="none" stroke="currentColor" stroke-linecap="round" stroke-linejoin="round" stroke-width="2" d="M21 12a9 9 0 1 1-6.219-8.56"/></svg></div>');
postAI.classList.add("noclick")
let GeminiFetch = "https://gemini.lzsay.com/v1/chat/completions"
try{
let postAIResult = document.querySelector(".post-ai-result")
let input = document.querySelector(".post-content").textContent
let inputHanzi = input.replace(/\n/g, '').replace(/[ ]+/g, ' ').replace(/<pre>[\s\S]*?<\/pre>/g, '').substring(0, 30000)
let toAI = `文章标题:${postTile},具体内容:${inputHanzi}`
const res = await fetch(GeminiFetch, {
headers: {
'Content-Type': 'application/json'
},
method: 'POST',
body: JSON.stringify({
model: 'doubaopro128k',
messages: [
{ role: 'system',content:`你是一个受过语言理解和摘要训练的高级人工智能。我希望你阅读以引号为分界的文本,并将其总结为一个简明的摘要段落。力求保留最重要的观点,提供一个连贯、可读的摘要,帮助人们理解讨论的要点,而无需阅读全文。请避免不必要的细节或切题。只给我输出结果,不提供其他信息。请不要用引号将回复包起来。`},
{ role: 'user', content: toAI }
],
})
})
// 读取整个响应体
const responseText = await res.text();
// 解析JSON数据
const data = JSON.parse(responseText);
const content = data.choices[0].message.content;
// 显示结果
postAIResult.textContent = `总结: ${content}`;
} catch (error) {
document.querySelector(".post-ai-result").remove();
console.log(error);
}
};
</script>